
Collection(컬렉션)
collection은 배열(array)의 단점을 개선하기 위해 만들어졌다.
array(배열)는 지정한 배열의 크기를 변경할 수 없고, 배열을 추가하거나 삭제하는 경우 인덱스를 변경해야 하는 불편함이 있다.
System.Collections
배열의 단점을 보완하기 위해 System.Collections라는 네임스페이스 안에 다양한 객체의 컬렉션을 정의한 클래스와 인터페이스들이 있다. 중요한 몇 가지 컬렉션들을 살펴본다.
collection(컬렉션)은 '수집, 더미, 모아놓은것'이라는 뜻이다.
1. ArrayList 클래스
ArrayList는 크기를 지정할 필요가 없다.
ArrayList는 네임스페이스에 포함되어 있으므로 선언하려면 using 키워드로 표시해야 한다.

# Add( )
요소를 추가할 때는 Add( )메서드를 사용한다.
*add : 더하다

10~12번줄에서 보듯이 컬렉션은 모든 타입을 저장할 수 있다.
추가한 요소를 인덱스를 이용해서 확인할 수 있다.

ArrayList는 선언할 때 크기를 지정하지 않았지만 요소를 추가하면 자동으로 크기가 늘어난다.
요소가 늘어나는지 확인하기 위해 Count 프라퍼티(속성)를 이용해서 확인해보자.
Count 프라퍼티는 네임스페이스 System.Collections.Generic 에 있는 List<T>클래스에 있으며 List에 있는 요소의 수를 가져오는 역할을 한다. Generic과 <T>에 대해서는 나중에 알아볼 것이다.

요소를 추가하기 전의 요소 개수와 추가한 후의 개수를 출력하면 된다.

# Remove( ) , RemoveAt( )
요소를 제거할 때는 Remove( )와 RemoveAt( )메서드를 사용한다.
*remove : 제거하다
*at : ~(위치)에
두 메서드는 Remove(제거할 요소) , RemoveAt(제거할 요소의 인덱스) 처럼 사용한다.


결과에서 볼 수 있듯이 ArrayList에 있는 요소를 삭제하면 자동으로 크기가 바뀌고 인덱스 번호도 수정된다.
# Insert( )
요소를 삽입할 때는 Insert( ) 메서드를 사용한다.
*insert : 추가하다, 삽입하다


2. Hashtable 클래스
Array와 ArrayList는 요소에 접근할 때 인덱스를 이용했다.
이런 점을 보완하기 위해 Hashtable을 만들었다.
hash(해시)라는 말은 어떤 데이터 값(value)을 다른 값으로 1:1 대응시키는 것 (이것을 mapping 이라고 함)을 말한다.
1:1 대응은 예를 들면 key1은 vaule1, key2는 value2에 연결하는 것이다.
이렇게 데이터를 mapping(매핑)을 이용해서 해시값 (또는 key값)을 만들어 연결해 두면 이것을 이용해서 요소의 위치를 찾을 때 즉시 알 수 있기 때문에 요소를 순서대로 확인하여 찾는 방법보다 훨씬 빠르게 접근할 수 있다.
mapping의 대표적인 예는 인터넷 주소인 IP와 도메인 이름의 연결이다.
인터넷에 연결된 모든 컴퓨터는 숫자로 되어 있는 인터넷 주소인 IP를 가지고 있다.
이 IP 숫자를 일일이 외우기 힘들기 때문에 도메인 이름, 예를 들어 google.com 같이 우리가 읽을 수 있는 문자로 표시할 수 있게 하고 이 둘을 매핑으로 연결해 둔 것이다. 그래서 검색창에 google.com을 입력하면 1:1 대응된 IP주소를 찾아서 연결해주는 것이다.
*table : 탁자, 표
Hashtable은 요소를 저장할 때 key(키)와 value(값)을 쌍으로 저장한다. 그 후 key를 사용해서 요소에 접근한다.

8번줄에 Hashtable을 인스턴스(객체)를 만들어서 testHashtable 변수에 저장했다.
12~14번줄에 요소를 추가하기 위해 Add메서드를 사용하고 인수는 (key, value) 형태로 입력한다.
즉, int라는 key(키)로 105라는 value(값)을 저장한다.
16~18번줄에 요소에 접근하기 위해 key를 이용한다.
20번줄에는 요소를 삭제하기 위해 Remove메서드를 사용하고 인수는 key를 입력한다.
3. Queue 클래스
Queue(큐)는 '줄'이라는 뜻이다.
컴퓨터의 데이터 구조에서 사용하는 Queue는 데이터를 저장하는 방법 중의 하나이다.
예를 들어 코로나 검사를 위해 일렬로 줄을 서 있는 모습을 생각하면 된다.
먼저 줄을 선 사람이 가장 먼저 처리되는 것처럼 가장 먼저 입력된 데이터가 가장 먼저 나가는 구조이다.
이것을 FIFO (First In First Out)라고 부른다.

9번줄에서 Queue객체를 생성하여 변수 testQueue에 저장했다.
13번줄 부터 데이터를 저장하기 위해 Enqueue( )메서드를 사용한다.
접두어 en은 '안으로'라는 뜻이 있다.
입력된 데이터는 testQueue에 들어온 순서대로 정렬된다.

Queue에 들어온 데이터는 인덱스나 key로 접근할 수 없지만 Dequeue메서드를 사용할 수 있다.
17번줄 부터 들어온 순서대로 요소를 반환하기 위해 Dequeue( )메서드를 사용한다.
접두어 de는 'away, 벗어나다'의 뜻이 있다.
Dequeue메서드는 들어온 순서대로 요소를 반환하는 동시에 요소를 제거한다는 것에 주의한다.
17번줄에서 가장 먼저 들어온 105를 반환하고 동시에 제거된다.
18번줄에서 가장 앞에 있는 Wraven을 반환하고 동시에 제거된다.
19번줄에서 가장 앞에 있는 3.14를 반환하고 동시에 제거된다.
결국 19번줄이 완료되면 testQueue에는 요소가 모두 삭제되어 아무것도 없는 상태가 된다.
만약 제거하지 않고 요소를 확인만 하고 싶으면 Peek( )메서드를 사용한다.
*peek : 훔쳐보다(글자 모양이 영락없이 두 눈을 돌리고 벽에 붙어 귀를 쫑긋 세운 모습이다.)


이 경우 가장 먼저 들어온 요소를 보여주므로 105만 확인할 수 있다.
두번째, 세번째 Peek메서드는 의미가 없다.
4. Stack 클래스
Stack은 Queue와 반대로 마지막에 들어온 데이터를 먼저 내보낸다.
LIFO (Last in First Out)
데이터를 입력하고 반환, 삭제할 때도 Queue의 메서드와 같은 기능을 하는 메서드가 있다.
Push( )는 Queue의 Enqueue( )
Pop( )은 Queue의 Dequeue( )와 같다.
Peek( )은 공통으로 사용한다.

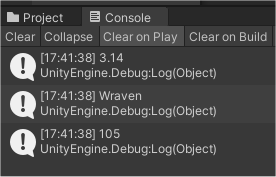
Queue와 반대로 제일 마지막에 입력된 데이터(3.14f)가 반환되고 삭제된다.
또한 Peek( )를 사용하면 제일 마지막에 입력된 3.14f만 확인할 수 있을것이다.
컬렉션의 단점
컬렉션은 편리한 기능을 제공하지만 단점도 있는데 그것은 시간이 많이 들어 성능을 저하시킨다는 것이다.
왜 성능을 저하시키는지 object타입의 경우를 예로 들어 설명한다.
이전에 '변수'에서 C#에는 모든 타입(Type)을 담을 수 있는 object 타입이 있다고 했다.
이 object타입은 메모리의 낭비와 오류의 위험성도 있다고 했다.
object타입은 모든 타입의 부모가 되는 타입이다.
즉, 모든 다른 타입은 object타입을 상속받는다.
그러므로 아래 예처럼 object타입에는 모든 값을 저장할 수 있고, 모든 타입을 object타입으로 타입변환 할 수 있다.


위의 결과를 보면 여러 가지 타입을 사용할 필요가 없는 것처럼 보인다.
하지만 object타입을 사용하면 성능에 저하시키는 치명적인 상황이 발생하는데 boxing(박싱), unboxing(언박싱) 이라고 부르는 2가지 경우가 있다.
boxing, unboxing
object타입은 reference(참조)타입이다.
그래서 value(값) 타입을 저장하기 위해서는 reference타입으로 변환(casting, 캐스팅) 과정을 거쳐야 저장할 수 있다.
이 과정을 boxing이라고 한다.

반대로 reference타입인 object 타입을 value타입에 저장하려면 unboxing 과정을 거친다.

이전 글 'struct 구조체'에서 reference타입과 value타입은 서로 다른 메모리를 사용한다고 했다.
reference타입은 Heap메모리, value타입은 Stack메모리를 사용하는데 이 두 메모리는 데이터를 저장하는 방식이 다르다.
그래서 서로 타입을 변환하면 그 만큼 시간이 많이 걸리게 된다.
단순하게 저장하는 것 보다 boxing은 20배, unboxing은 4배 더 시간이 소요된다고 한다.
ArrayList 등과 같은 컬렉션에 모든 타입의 값을 담을 수 있는 이유는 바로 object타입으로 저장하기 때문이다.
그러므로 컬렉션은 데이터를 추가할 때 boxing, 불러올 때 unboxing이 발생하며 이 cast(타입 변환)으로 인해 데이터 처리 속도가 저하되는 것은 피할 수 없다.
컬렉션의 이런 단점을 보완하기 위해 만들어진 것이 generic(제네릭)이다.
다음 글에서 살펴본다.
끝.
Wraven...
'취미로 하는 게임코딩_gameCodingAsHobby > 유니티unity로 게임 만들기' 카테고리의 다른 글
| 유니티38_C#_23_FileStream 파일스트림 (2) | 2021.03.24 |
|---|---|
| 유니티37_C#_22_Generic 제네릭 (0) | 2021.03.22 |
| 유니티35_C#_20_static 스태틱 (0) | 2021.03.22 |
| 유니티34_C#_19_String 문자열 (0) | 2021.03.20 |
| 유니티33_게임 제작 과정 11_적 랜덤 위치 소환 (0) | 2021.03.19 |



